
In front end development, front end engineering is always accompanied by the whole development process. In our commonly used project packaging tools, whether it’s webpack or rollup, they all have a very powerful capability — tree-shaking. So, what is the principle of tree-shaking? The core principle is actually AST.
In fact, there are many applications of AST in front end development, such as webpack, a packing tool we frequently use in front-end projects, Eslint, a code inspection tool, and Babel, a code conversion tool all rely on the syntax analysis and conversion capabilities of AST.
AST Simple Introduction
AST is the abbreviation of Abstract Syntax Tree, which can be used to describe the syntax structure of our code.
Here’s an example:
| |
I created a file ast.js here, which can be understood as a File node to store the program body, and inside it are our JavaScript syntax nodes. The root node of our JavaScript syntax nodes is Program, and we have defined two nodes in it. The first node is let a = 1, which is parsed as AST is VariableDeclaration, that is a variable declaration node. The second node is function add() {}, which is parsed as AST is FunctionDeclaration, that is, a function declaration node.
Here I recommend a platform: AST Explorer, where you can clearly see the result of JavaScript code translated into AST. If you look at the picture below, you’ll understand it at a glance:
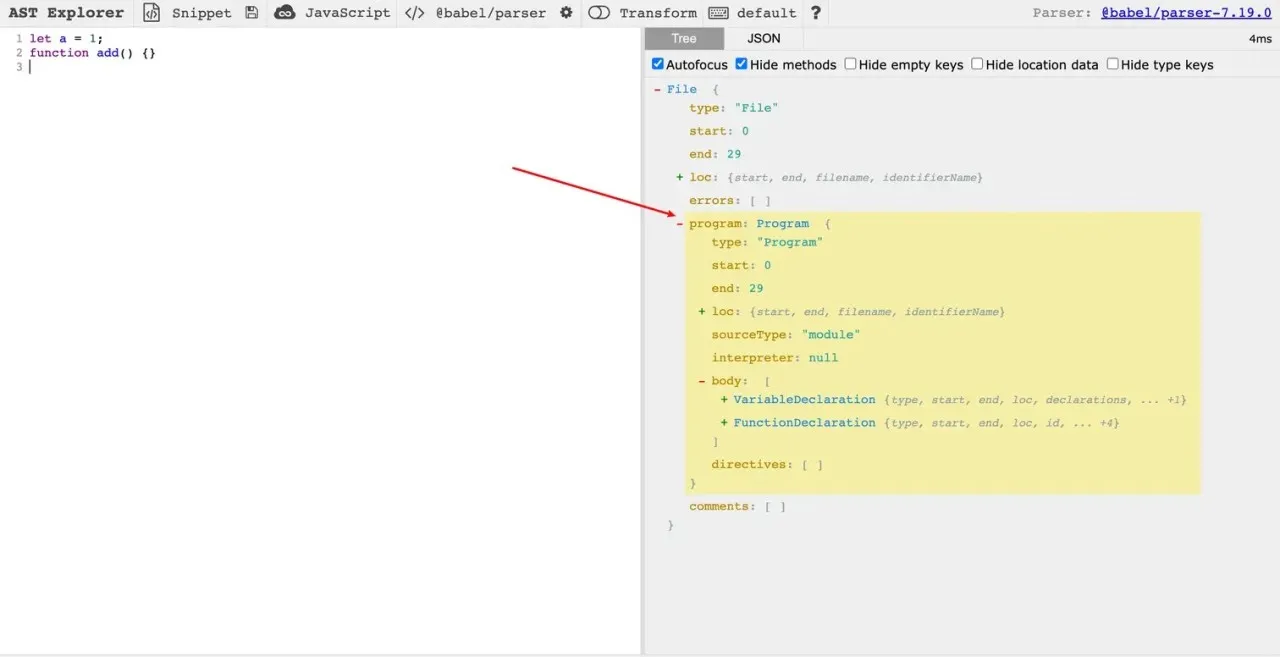
Role of AST
What can we do with the ast information of the code?
Code analysis and conversion. AST can parse our code into an ast tree, naturally we can process and convert this tree, the most classic application of which has to be babel, which converts our high-level syntax ES6 into ES5, and then transforms the ast tree into code output. In addition, the processing of ES6’s import and export by webpack also depends on the capabilities of ast, as well as the syntax conversion of our jsx, etc.
Syntax checking and error hinting. After parsing the syntax into an ast tree, we can naturally check its syntax for correctness according to certain syntactic rules, and if there is an error, we can throw it out and remind the developer to correct it. For example, vscode that we use is using AST to provide real-time syntax checking and error hinting. In front-end projects, the most widely used syntax checking tool is ESLint, which is basically essential for front-end projects.
Static type checking. This is a bit like the second point, but the second point is focused on syntax checking, while this is for type checking, for example, our Typescript will use ast for type checking and inference.
Code refactoring. Based on the AST tree, we can automatically refactor the code, such as extracting functions, renaming variables, upgrading syntax, moving functions, etc.
In fact, in practical development, we can use it to do a lot of things, such as automatic burying, automatic internationalization, dependency analysis and governance, etc. Interested partners can explore on their own.
And today I am mainly introducing a major application of AST, which is the powerful Tree-Shaking capability of our webpack.
Tree-shaking
The translation of Tree-shaking is shaking the tree. This tree can be metaphorically a tree in reality, and can be understood as such, shaking the tree is to shake off the leaves that are yellowing, serving no function and still absorbing nutrients. To move this into the JavaScript program is to remove the unused code (dead-code) in the JavaScript context.
Without further ado, let’s look at the example:
| |
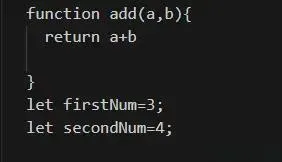
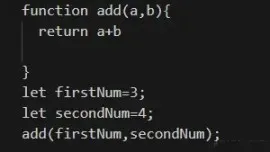
In this code, we define two functions, add and multiple, two variables firstNum and secondNum, and then call the add method and pass firstNum and secondNum as parameters.
Clearly, the multiple method is not called, and can actually be deleted during packaging to reduce the size of our packaged code.
So, how to delete multiple? It’s time for our ast to come on stage! To achieve this function, there are three steps.
Step 1: Parse source code to generate AST
Look at this example:
| |
We choose acorn to parse our code (babel is actually based on acorn for implementing parsers). Before executing, we need to install acorn by running npm install acorn, then read the file content and pass it into acorn to get AST.
We can use AST Explorer to view our current AST.
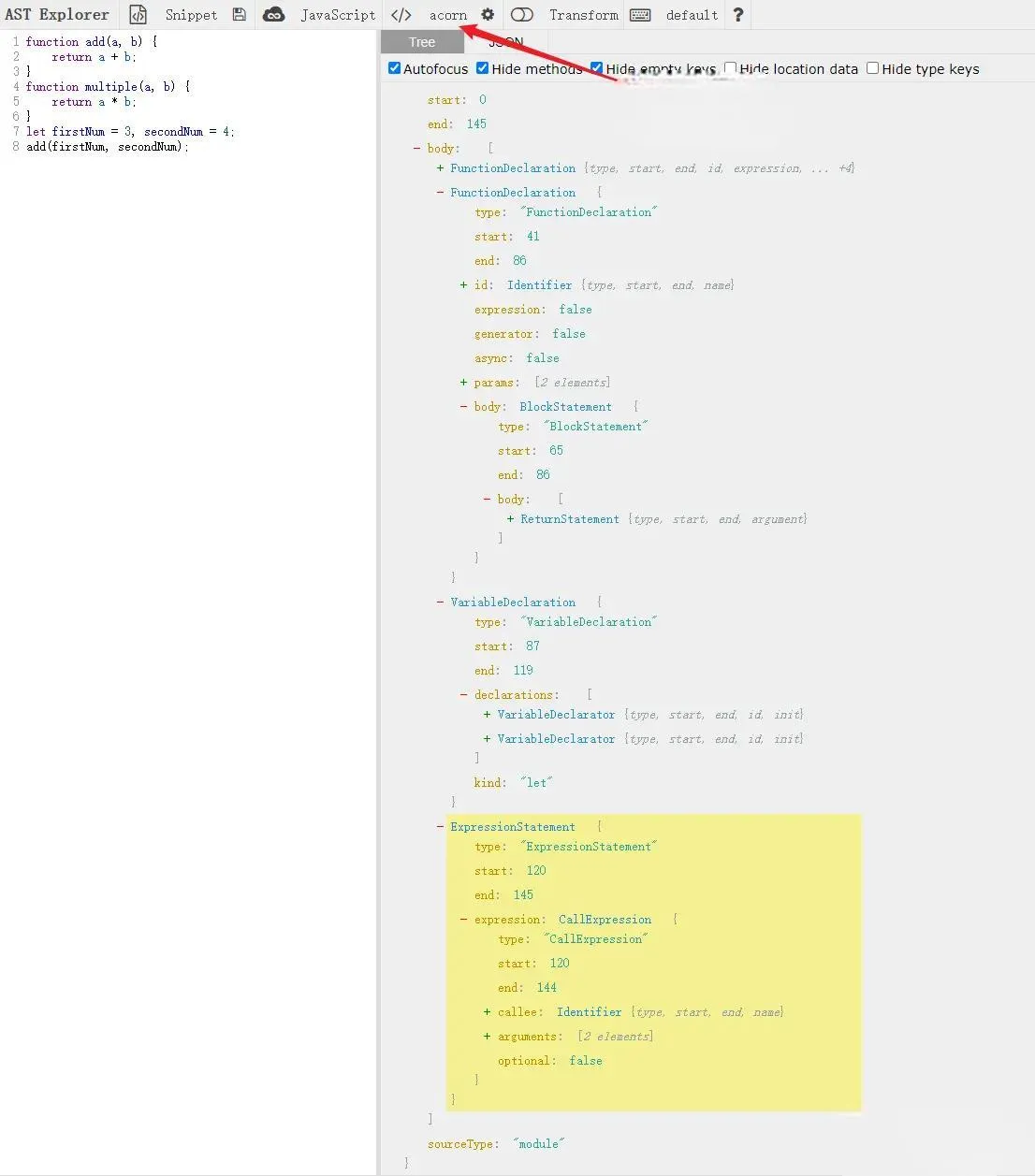
Step 2: Traverse AST, record relevant information
What information do we need to record?
Our main goal is to collect unused code and then delete it. Thus the two pieces of information we would primarily think to collect are:
Collect all function nodes or variable type nodes
Collect all used function nodes or variable type nodes
Let’s try:
| |
I’ve introduced a Generator here whose function is to transform each AST node into the corresponding code. Let’s look at the implementation of Generator:
- First, define the Generator class and export it.
| |
- Then, define the run method and the visitNode and visitNodes methods.
run: calls the visitNodes method to generate code.
visitNode: based on the node type, calls the corresponding method for the corresponding processing.
visitNodes: handles array type nodes. Internally, it loops and calls the visitNode method.
| |
Next, we’ll discuss how each method that processes a node type is implemented:
Implement the visitVariableDeclaration method
| |
visitVariableDeclaration processes nodes such as let firstNum = 3 in variable declarations. node.kind represents let/const/var. Then, multiple variables can be declared at once, such as let firstNum = 3, secondNum = 4; in our test.js, which gives us two nodes in node.declarations.
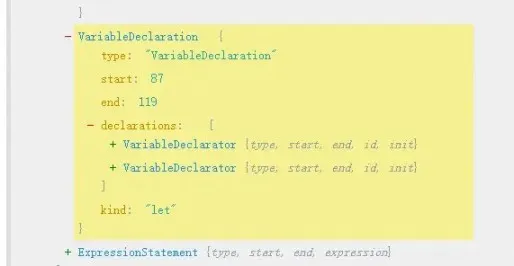
Implement the visitVariableDeclarator method
| |
visitVariableDeclarator is a child node of the above VariableDeclaration, which can receive the kind of the parent node. For example, let firstNum = 3, here id is the variable name firstNum, and init is the initial value 3.
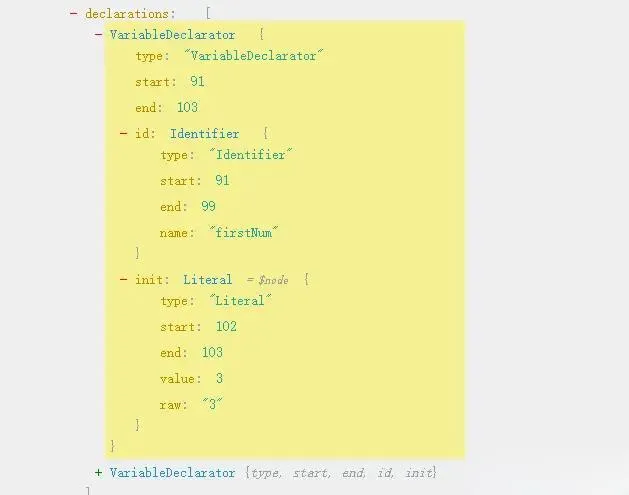
Implement the visitLiteral method
| |
In Literal we have literals, like the 3 in let firstNum = 3, which is a string literal. In addition to this, there are numeric literals, boolean literals, etc., we just need to return its raw attribute.
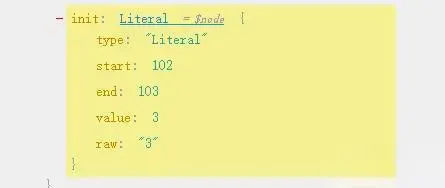
Implement the visitIdentifier method
| |
Identifier refers to identifiers, such as variable names, attribute names, parameter names, etc. For example, for let firstNum = 3, the firstNum. We just need to return its name attribute directly.

Implement the visitBinaryExpression method
BinaryExpression refers to binary expressions, like addition, subtraction, multiplication, and division operations in our case. For instance, the AST for “a + b” is like this:
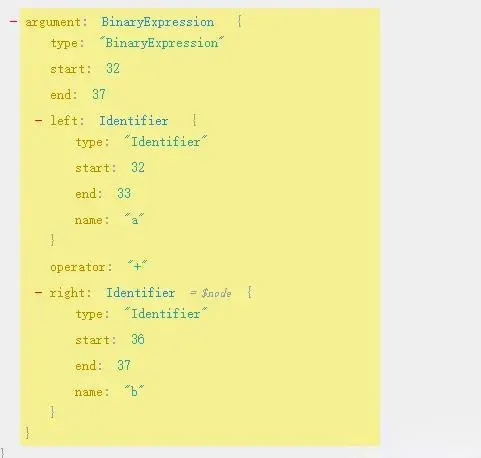
We need to join its left and right nodes and the middle identifier.
| |
Implement the visitFunctionDeclaration method
FunctionDeclaration refers to function declaration nodes. It’s a bit more complex as we need to join a function together.
| |
For example, the AST for our add function is:
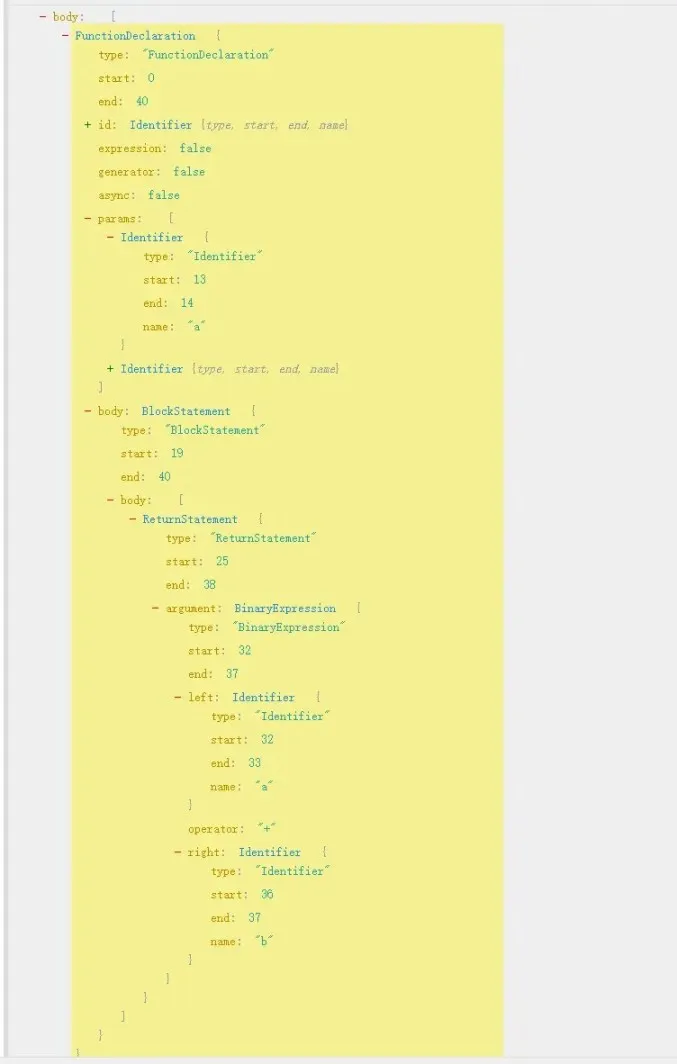
| |
First get node.id, which is add. Then, process the arguments (params) of the function. Because there may be multiple params, we need to loop through and join them with commas. Finally, call the visitNode method to join the node.body function body.
Implement the visitBlockStatement method
BlockStatement refers to block statements, which is the part enclosed by braces. For example, the AST for the block statement in our add function is:
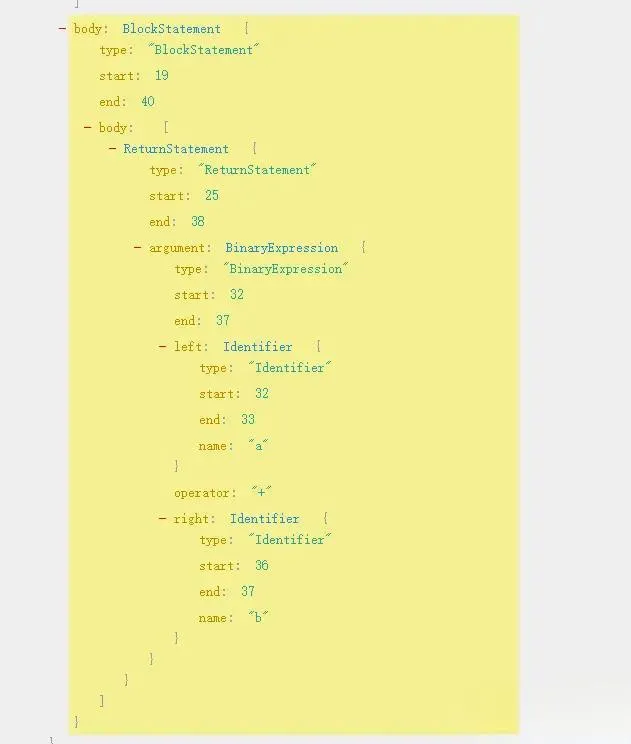
| |
We just need to use the visitNodes function to join its node.body.
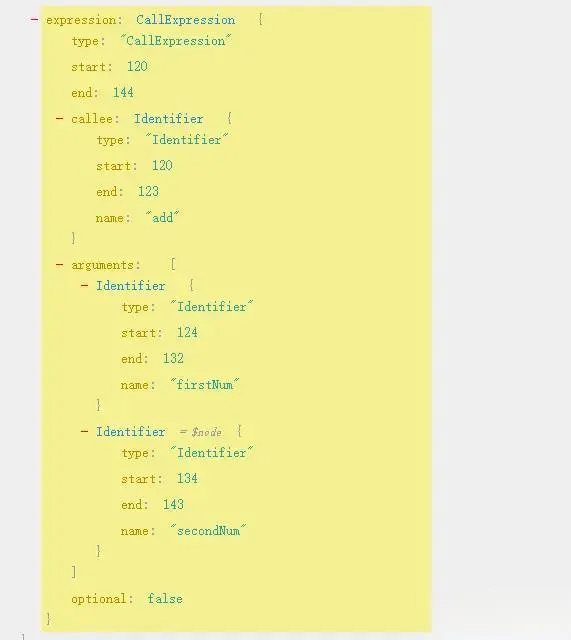
Implement the visitCallExpression method
CallExpression refers to function calls, for example, add(firstNum, secondNum). Its important attributes are:
callee: which is add
arguments: which are the parameters firstNum and secondNum passed when calling.
| |
We just need to join its callee and the arguments in parentheses ().
Implement the visitReturnStatement method
ReturnStatement refers to return statements, like return a + b. Its AST is:

It’s also relatively simple to implement, just joining node.argument directly:
| |
Implement the visitExpressionStatement method
ExpressionStatement refers to expression statements, that have return values when executed, such as add(firstNum, secondNum);. This is wrapped around CallExpression with an ExpressionStatement, and returns the result of the function call after execution. The AST is as followed:
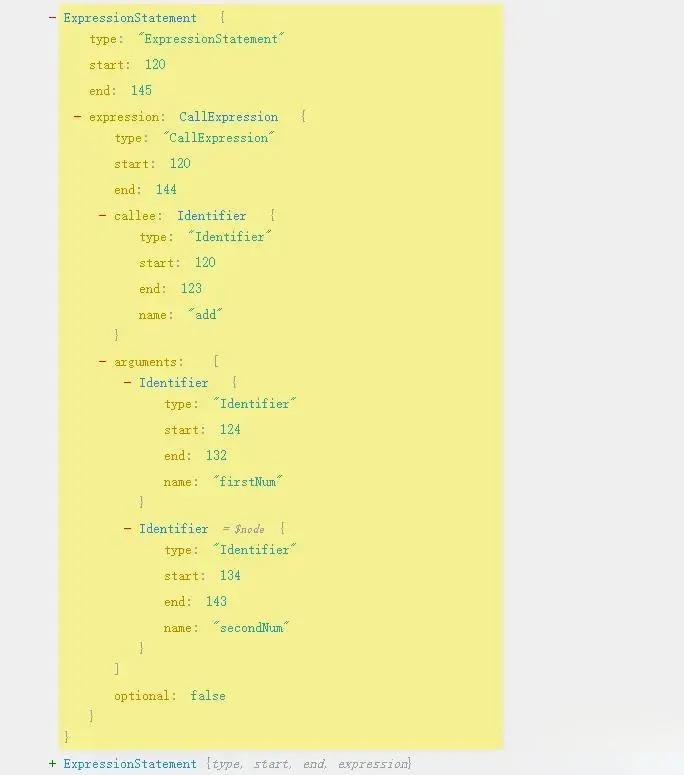
So the implementation is simple, we just need to process and return its expression.
| |
This way, we have fully implemented the Generator. Now we can start traversing the AST.
| |
Run it with node tree-shaking.js, the result is:

It’s obvious that we have four nodes, function or variable type nodes in decls, and only three have been called in calledDecls. Notably, the multiple function has not been called and can be tree-shaken. After getting this information, we can now start generating the code after tree-shaking.
Step 3: Generate new code based on the information obtained in Step 2
| |
We directly traverse calledDecls to generate new source code, and the print result is as follows:
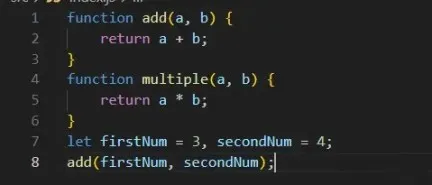
Hmm! When comparing it with our original file, although multiple has been removed, our function call statement add(firstNum, secondNum); is missing. Let’s handle this situation simply.
We declare a code array:
| |
We store the information that doesn’t belong to FunctionDeclaration and VariableDeclaration:
| |
When printing the output, make sure to include the information from the code array:
| |
Then, we run it and print the result:
Now, we have completed a simple version of tree-shaking. Of course, webpack’s tree-shaking capability is much stronger. We just wrote the simplest version, and real projects are much more complicated.
Processes file dependencies (import/export)
Handles scopes
Recursive tree-shaking. As it’s possible that removing some code will produce new unused code, it needs to be handled recursively.
And much more…