Differences between HTML, XML and XHTML
HTML: Hypertext Markup Language, is a somewhat loose and not strict Web language;
XML: Extensible Markup Language, mainly used for storing data and structures, is extensible;
XHTML: Extensible Hypertext Markup Language, based on XML, its function is similar to HTML, but the syntax is more strict.
What are the differences and connections between HTML, XHTML and HTML5
Differences between XHTML and HTML
XHTML tag names must be lowercase;
XHTML elements must be closed;
XHTML elements must be nested correctly;
XHTML elements must have a root element.
Differences between XHTML and HTML5
HTML5 adds the canvas drawing element;
HTML5 adds the video and audio elements for media playback;
More semantic tags, easier for browsers to recognize;
Better support for local offline storage;
MATHML, SVG, etc., can be rendered better;
Added new form controls: calendar, date, time, email, etc.
The connection between HTML, XHTML, and HTML5
XHTML is a specification version of HTML;
HTML5 is the new standard for HTML, XHTML, and HTML DOM.
What are the elements in the line? What are block-level elements? What are void elements ?
Inline elements:
a,b,span,img,input,select,strong;Block-level elements:
div,ul,li,dl,dt,dd,h1-5,p, etc;Void elements:
<br>,<hr>,<img>,<link>,<meta>.
Use the difference between link and @import when importing styles for pages
link is an HTML tag, while
@importis provided by css;When the page is loaded,
linkwill be loaded at the same time, while the css referenced by@importwill be loaded after the page is loaded;@importis only recognized in IE5 and above, while link is an XHTML tag, with no compatibility issues;The weight of the styles in the
linkway is higher than the weight of@imort
How to understand semantic tags
Concept:
Semantic tagging refers to choosing appropriate tags based on the content’s structure (content semantics), which not only facilitates developers to read and write more elegant code, but also allows for web crawlers and machines to parse effectively.
Benefits of Semantic Tagging
Use the correct tags for the right tasks;
When styles are removed or lost, the page can still present a clear structure;
It facilitates other devices (such as screen readers, readers for the blind, mobile devices) to render web pages in a meaningful way;
Beneficial for SEO: Establishes good communication with search engines, aiding web crawlers to collect more effective information. Web crawlers depend on tags to determine context and the weight of various keywords;
It facilitates team development and maintenance. Semantic tagging is more readable. Teams that follow the W3C standard all stick to this standard, which can reduce differentiation.
What is the difference between a property and an attribute
property is a property in DOM, it’s an object in JavaScript;
attribute is a feature on HTML tags, and its value can only be a string;
In simple terms: Attribute is a built-in property of DOM nodes, such as frequently used id, class, title, align etc in html; while Property is an additional content as an object of this DOM element, such as childNodes, firstChild etc.
What are the new features of html5 and what elements have been removed?
New Features
HTML5 is no longer a subset of SGML, mainly about the addition of images, location, storage, multi-tasking and other features.
Drag and drop API;
Better semantical content tags (header, nav, footer, aside, article, section);
Audio, video API (audio, video);
Canvas API;
Geolocation API;
Local offline storage localStorage for long-term data storage, data will not be lost even after closing the browser;
sessionStorage data is automatically deleted after closing the browser;
Form controls: calendar, date, time, email, url, search;
New technologies such as webworker, websocket, Geolocation, etc.
Removed Elements
Pure presentation elements:
<basefont>Default font, if no font is set, it will render with this;<font>Font tag;<center>Horizontal center;<u>Underline;<big>Font;<strike>Strikethrough text;<tt>Monospaced text.
Elements that negatively affect usability:
<frameset>, <noframes> and <frame>.
What is the structure of a front-end, where style and behavior are separated? And what are the benefits of separation?
Structure, Style and Behavior Separation
If we compare frontend to a person as an example, the structure (HTML) is akin to the “skeleton” of the human body, style is like the “decoration” of the body, such as clothes, jewelry, etc.; behavior is equivalent to a series of “actions” made by people.
In structure, style and behavior separation, the three are separated, each responsible for its own content, and each part can be used by reference.
On the basis of separation, we need to achieve: simplicity, reusability, and orderliness of our code.
Benefits of Separation
Code separation is conducive to team development and later maintenance;
Reduces maintenance costs, improves readability and provides better compatibility.
How to optimize your website’s files and resources
File merging (the purpose is to reduce http requests);
File compression (the purpose is to directly reduce the download volume of the file);
Use cache;
Use cdn to host resources;
gizp compress the required js and css files;
Backlinks, website external link optimization;
Meta tag optimization (title, description, keywords), heading tag optimization, alt optimization.
What is the concept of local storage in Html5, what are the advantages and how is it different from cookies?
HTML5’s Web storage features two types of storage: sessionStorage and localStorage.
sessionStorage is used for locally storing data within a session, which is destroyed after the session ends;
Unlike sessionStorage, localStorage is used for persistent local storage. Unless the user actively deletes the data, it will never expire;
A cookie is data stored locally on the user’s terminal (Client Side) by a website to identify user’s identity (usually encrypted).
Differences:
Data transfer between the browser and server: cookie data is always carried within the same origin’s http requests (even if it’s not necessary), meaning cookie data is passed back and forth between browser and server. Whereas sessionStorage and localStorage don’t automatically send data to the server and only save data locally.
Size: The storage size limit is different. cookie data cannot exceed 4K and is only suitable for storing very small data; sessionStorage and localStorage also have storage size limits, but it’s much larger than cookie, it can reach up to 5M or larger.
Data lifespan: sessionStorage is instantly closed when the session closes, so it’s not persistent; cookie is effective until the set cookie expiration time, even if the window or browser is closed. Whereas localStorage is always effective.
Scope: sessionStorage is not shared across different browser windows, even for the same page; whereas localStorage and cookie can be shared across all same-origin windows.
What are the common browser kernels
Trident kernel: Originally developed or used by IE, 360 browser;
Webkit kernel: Google Chrome, Safari, etc;
Gecko kernel: Mozilla FireFox, K-Meleon browser;
Presto kernel: Opera browser.
What is LocalStorage used for in HTML5?
localStorage local storage is like a lightweight database, it can permanently store data locally (unless manually deleted). In addition, it can also read locally cached cookies in the event of a network outage.
Use localStorage to save data: localStorage.setItem(key, value);
Use localStorage to retrieve saved data: localStorage.getItem(key);
Clear localStorage saved data: localStorage.removeItem(key);
Clear all data saved in localStorage object: localStorage.clear( );
Why Utilizing Multiple Domains to Store Website Resources is More Effective
Easier CDN caching;
Break browser’s concurrent limitations;
Save cookie bandwidth;
Save the number of connections to the main domain and optimize the response speed of the page;
Prevent unnecessary security issues;
The difference between several image formats in HTML and their use
There are currently two types of images:
Bitmap
Vector
Bitmap
A so-called bitmap is an image made up of pixels, also known as a raster image. The png, jpg, joeg, progressive jpeg, etc. images we use are bitmaps.
Vector
A vector image, also known as a vector graphic. Vector images do not record the information of each point on the screen, but record the algorithm of the element’s shape and color. When you open a vector image, the software calculates the function corresponding to the graphic and displays the results, the shape and color of the graphic, for you to see.
No matter whether the display screen is large or small, the algorithm corresponding to the object on the screen is unchanged. Therefore, even if the screen is scaled to a very large multiple, it will not become distorted like a bitmap.
The most common format is svg.
What are DNS
DNS stands for Domain Name System.
It is a distributed database on the World Wide Web that maps domain names to IP addresses, making it easier for users to access the Internet without having to remember IP strings that can be directly read by machines. The DNS protocol runs on top of the UDP protocol and uses port number 53.
Simply put, the process of obtaining the IP address corresponding to a domain name through the domain name is called domain name resolution (or hostname resolution).
| |
Where there is DNS, there is cache. The browser, operating system, local DNS, and root domain server will cache the DNS result to some extent.
The DNS query process is as follows:
First, it searches the browser’s own DNS cache. If it exists, the domain name resolution is completed here.
If the corresponding entry cannot be found in the browser’s own cache, it will try to read the host file of the operating system to see if there is a corresponding mapping relationship. If there is, the domain name resolution is completed here.
If there is no mapping relationship in the local hosts file, it will look up the local DNS server (ISP server, or manually set DNS server). If it exists, the domain name resolution is completed here.
If the local DNS server still can’t find it, it will send a request to the root server for recursive query.
Strong Cache
When the browser loads resources, it first determines whether to hit the strong cache based on the header information of the local cache resources. If the hit is made, it directly uses the resources in the cache and will not send a request to the server again.
The header information here refers to expires and cache-control.
Expires
This field is a specification in http1.0. Its value is an absolute time GMT formatted time string, such as Expires: Mon, 18 Oct 2066 23:59:59 GMT. This time represents the expiration time of this resource. Before this time, it hits the cache. This method has a clear disadvantage, because the expiration time is an absolute time, so when the server and client time deviation is large, it will cause cache chaos (local time can also be changed at will).
Cache-Control (priority over Expires)
Cache-Control is header information that appeared in http1.1. It mainly uses the max-age value of this field to make judgments. It is a relative time. For example, Cache-Control: max-age=3600, which means that the validity period of the resource is 3600 seconds. In addition to this field, cache-control also has the following commonly used setting values:
no-cache: Need to use cooperative cache, send a request to the server to confirm whether to use the cache.
no-store: Prohibit the use of caches, and you need to request data again every time.
public: Can be cached by all users, including end users and CDN and other intermediate proxy servers.
private: It can only be cached by the end user’s browser, and it does not allow CDN and other relay cache servers to cache it.
Cache-Control and Expires can be enabled on the server side at the same time. When enabled at the same time, Cache-Control has a higher priority.
negotiation cache
When the strong cache does not hit, the browser will send a request to the server, and the server will judge whether to hit the cache based on some information in the header. If it hits, it returns 304 and tells the browser that the resource has not been updated and can use the local cache.
The information in the header here refers to Last-Modify/If-Modify-Since and ETag/If-None-Match.
Last-Modify/If-Modify-Since
The first time the browser requests a resource, the server will add Last-Modify to the header returned. Last-modify is a time that identifies the last modification time of this resource (it can only be accurate to seconds, so requests with intervals less than 1 second cannot detect file changes).
When the browser requests this resource again, the request header of the request will contain If-Modify-Since, which is the Last-Modify returned before the cache. After receiving If-Modify-Since, the server judges whether to hit the cache based on the last modification time of the resource.
If the cache is hit, it will return 304, and it will not return the resource content, nor will it return Last-Modify.
Disadvantages:
The resource has changed in a short time, Last-Modified will not change.
Periodic changes. If this resource is modified back to its original state within a cycle, we think it is possible to use the cache, but Last-Modified does not think so, so there is ETag.
ETag/If-None-Match
Etag is encoded based on file content, which can ensure that if the server is updated, it will definitely request resources again, but encoding requires additional overhead.
Different from Last-Modify/If-Modify-Since, ETag/If-None-Match returns a checksum. ETag can guarantee that each resource is unique, and the change of resources will lead to the change of ETag. The server determines whether to hit the cache according to the If-None-Match value uploaded by the browser.
Unlike Last-Modified, when the server returns a 304 Not Modified response, the ETag has been regenerated, and this ETag will be returned in the response header, even if this ETag has not changed from before.
Last-Modified and ETag can be used together, and the server will verify ETag first. Only when they are consistent, will it compare Last-Modified again, and finally decide whether to return 304.
How many processes will appear at least when opening a Tab page in Chrome browser?
The latest Chrome browser includes at least four: 1 Browser main process, 1 GPU process, 1 Network process, multiple rendering processes and multiple plugin processes, of course, there are more complex situations;
If there are iframes on the page, the iframe will be separated into processes
If there are plugins, the plugin will also start a process
ultiple pages belong to the same site, and if page a opens page b, they will share one rendering process
If extensions are installed, the extensions will also occupy processes
These processes can be viewed through the Chrome Task Manager.
Even with the current multi-process architecture, we still encounter situations where a single page freezes, ultimately leading to the crash of all pages. Can you explain your understanding of this?
Let’s consider a situation that involves the same site, and we can expand on this.
Chrome’s default policy is to assign one rendering process to each tab. However, if a new page is opened from an existing page and the new page belongs to the same site as the existing page, then the new page will reuse the rendering process of the parent page. The official name for this default policy is ‘process-per-site-instance’.
To put it simply, if multiple pages belong to the same site, these pages will be assigned to one rendering process. So, there is a situation where if one page crashes, it will lead to the crash of other pages on the same site, because they are using the same rendering process.
Why would they be put into one process?
Just think about it: for sites that belong to the same parent, such as the following three:
If they are in one rendering process, they will share the JavaScript execution environment, which means that scripts in Page A can be directly executed in Page B. There are demands for this sometimes.
Could you explain the process of establishing a TCP connection, and why three handshakes are needed?
Three-way Handshake
First handshake
The client sends a connection request segment to the server. The header of this segment has SYN=1, ACK=0, seq=x. After the request is sent, the client enters the SYN-SENT state.
PS1: SYN=1, ACK=0 signifies that this segment is a connection request segment.
PS2: x signifies the initial sequence number of the byte stream for this TCP communication.
It is stipulated in TCP that segments with SYN=1 cannot have a data part, but consume a sequence number.
Second handshake
After the server receives the connection request segment, if it agrees to the connection, it will send a response: SYN=1, ACK=1, seq=y, ack=x+1. After the response is sent, it enters the SYN-RCVD state.
PS1: SYN=1, ACK=1 signifies that this segment is a connection acceptance response segment.
PS2: seq=y signifies the initial sequence number of the byte stream when the server acts as the sender.
PS3: ack=x+1 signifies that the server hopes that the sequence number of the next data segment sent starts from x+1 byte.
Third handshake
When the client receives the connection acceptance response, it needs to send another confirmation segment to the server to confirm: the server’s connection acceptance response has been successfully received.
The header of this segment is: ACK=1, seq=x+1, ack=y+1.
After the client sends this segment, it enters the ESTABLISHED state. When the server receives this response, it also enters the ESTABLISHED state. At this point, the connection establishment is complete!
Why is a three-way handshake needed for the connection establishment, instead of a two-way handshake?
The book “Computer Networks” by Xie Xiren states that the purpose of a “Three-way handshake” is “to prevent suddenly delivering outdated connection request segments to the server, thus causing errors”.
In another classic “Computer Networks” book, the purpose of a “Three-way handshake” is to solve the problem of “delayed duplicate groups in the network”. These two different descriptions actually clarify the same issue.
In Xie Xiren’s “Computer Networks” example, the occurrence of “outdated connection request segments” occurs in the following situation: the client’s first connection request segment did not get lost, but was detained in a network node for a long time, thus delaying the connection release to a certain time later when it reaches the server. This is an outdated segment. But when the server receives this outdated connection request segment, it mistakenly believes that it is a new connection request sent by the client again. So, it sends a confirmation segment to the client agreeing to establish a connection. If a “Three-way handshake” is not used, as long as the server sends a confirmation, a new connection is established. Since the client did not send a request to establish a connection at this time, it will ignore the server’s confirmation and will not send data to the server. But the server thinks that the new transport connection has been established and is always waiting for the client to send data. In this way, a lot of server resources are wasted. The method of “Three-way handshake” can prevent the above phenomenon from happening. For example, in just such a case, the client will not confirm the server’s confirmation. The server, not receiving a confirmation, knows that the client has not requested to establish a connection.
Four-way Handshake
First handshake
If A believes that data transmission is complete, it needs to send a connection release request to B. This request only has a header, the main parameters carried in the header are:
FIN=1, seq=u. At this point, A enters the FIN-WAIT-1 state.
PS 1: FIN=1 signifies that this segment is a connection release request.
PS 2: seq=u, where u-1 is the sequence number of the last byte A sends to B.
Second handshake
After B receives the connection release request, it informs the corresponding application program that the connection from A to B has been released. At this point, B enters the CLOSE-WAIT state and sends a connection release response to A. The header of the response contains:
ACK=1, seq=v, ack=u+1.
PS1: ACK=1: except for the TCP connection request segments, all data packets in the TCP communication process have ACK=1, which means a response.
PS2: seq=v, where v-1 is the sequence number of the last byte B sends to A.
PS3: ack=u+1 means that B wants to receive segments starting from the u+1th byte and has successfully received the first u bytes.
Once A receives the response, it enters the FIN-WAIT-2 state and waits for B to send a connection release request.
After the second handshake, the connection from A to B has been released, B will no longer receive data, and A will no longer send data. But the connection from B to A still exists, B can continue sending data to A.
Third handshake
After B sends all data to A, it sends a connection release request to A, the request header: FIN=1, ACK=1, seq=w, ack=u+1. B enters the LAST-ACK state.
Fourth handshake
After A receives the release request, it sends a confirmation response to B, and A enters the TIME-WAIT state. This state lasts for 2MSL. If B does not retransmit the request during this time, A enters the CLOSED state and revokes the TCB. When B receives the confirmation response, it also enters the CLOSED state and revokes the TCB.
Why does A have to enter the TIME-WAIT state first, and wait for 2MSL before entering the CLOSED state?
This is to ensure that B can receive the confirmation response from A.
If A directly enters the CLOSED state after sending the confirmation response, then if this response is lost, B will resubmit the connection release request after waiting for a timeout. But at this point, A has closed and will not respond in any way, so B will never be able to close normally.
What happens between entering a URL and the display of a webpage?
URL Parsing
Firstly, judge whether what you input is a valid URL or a keyword to be searched, and act according to your input.
DNS Query
Query the corresponding IP through DNS.
TCP Connection
After determining the IP address of the target server, it goes through a three-way handshake to establish a TCP connection.
HTTP Request
After the TCP connection is established, communication can be based on this. The browser sends an HTTP request to the target server.
Responding to request
When the server receives the browser’s request, it will carry out logical operations. After the operations are completed, it will return an HTTP response message.
Page Rendering
When the browser receives the resources in the server’s response, it first parses the resources:
Look at the information in the response header and handle it correspondingly according to different instructions, such as redirection, storing cookies, unzipping gzip, caching resources, etc.
Look at the Content-Type value in the response header, adopting different parsing methods according to different resource types.
The rendering process of the page is as follows:
Parse HTML and build a DOM tree.
Parse CSS and generate a CSS rule tree.
Merge the DOM tree and CSS rules to generate render tree.
Layout the render tree (Layout / reflow), responsible for calculating the size and position of each element.
Draw the render tree (paint), drawing the pixel information of the page.
The browser will send the information of each layer to the GPU, and the GPU will composite each layer and display it on the screen.
CDN
The full name is Content Delivery Network.
A Content Delivery Network (CDN) is a network of interconnected servers that can speed up the loading of web pages for data-intensive applications. CDN can stand for Content Delivery Network or Content Distribution Network. When a user visits a particular website, data from the website’s server needs to be transmitted over the internet to the user’s computer. If the user is far away from the server, loading large files (such as videos or website images) will take a long time. In contrast, if the website content is stored on a CDN server closer to the user, it can reach their computer faster.
CDN Cache
As for CDN cache, after the local cache of the browser becomes invalid, the browser will initiate a request to the CDN edge node. Similar to browser cache, there is also a cache mechanism at the CDN edge node. The caching strategies of CDN edge nodes are different for different service providers, but generally, they will follow the HTTP standard protocol and set the data cache time of the CDN edge node with the Cache-control: max-age field in the HTTP response header.
When the browser requests data from the CDN node, the CDN node will judge whether the cache data has expired. If the cache data hasn’t expired, it would directly return the cache data to the client; otherwise, the CDN node will issue a request to the server for fresh data, pull the latest data from the server, update the local cache, and return the latest data to the client. CDN service providers generally provide CDN cache durations based on multiple dimensions such as file suffixes and directories, and provide more refined cache management for users.
Advantages of CDN
The CDN node solves the problem of cross-operator and cross-regional access, greatly reducing access latency. Most requests are completed at the CDN edge node. The CDN plays a role in diversion, reducing the load on the source server.
Difference between HTTP and HTTPS
HTTPS is a secure version of the HTTP protocol. The data transmission of the HTTP protocol is in plain text, which is insecure, whereas HTTPS encrypts data through the SSL/TLS protocol, making it relatively more secure.
HTTP and HTTPS use different connection methods and default ports. HTTP uses port 80, while HTTPS uses port 443.
Due to the need for encryption and multiple handshakes, HTTPS doesn’t perform as well as HTTP in terms of performance.
HTTPS requires SSL, and SSL certificates have a cost. The stronger the certificate’s functionality, the higher the cost.
Webpack fingerprinting strategy: hash, chunkhash, contenthash
hash strategy: It’s based on the project. If the project content changes, a new hash will be generated. If the content doesn’t change, then the hash will stay the same.
chunkhash strategy: It’s based on the chunk. If a file’s content changes, then the hash of the corresponding chunk group module will change.
contenthash strategy: It’s based on its own content.
Recommended usage:
For css, use contenthash.
For js, use chunkhash.
Webpack build process
Initialize parameters: Parse the webpack configuration parameters, merge the parameters passed in by the shell and the parameters configured in the webpack.config.js file to form the final configuration result.
Start compiling: The parameters obtained from the previous step are used to initialize the compiler object, register all configured plugins, and the plugins will listen to the event nodes of the webpack build lifecycle and respond accordingly. Run the ‘run’ method of the object to start compiling.
Determine the entry point: Starting from the configured ‘entry’ point, parse the file to build the AST syntax tree, find out dependencies, and then recurse.
Compile modules: During the recursion, according to the file type and the ‘loader’ configuration, call all configured loaders to transform the file, then find out the modules that this module depends on, and recurse this step until all files dependent on the entry have been processed by this step.
Complete module compilation: After using the loader to translate all modules in the fourth step, you get the final content of each module after translation and their dependencies.
Output resources: According to the dependencies between the entry and the modules, assemble them into chunks each containing multiple modules, then transform each chunk into a separate file and add it to the output list. This is the last chance to modify the output content.
Output completion: After determining the output content, determine the output path and filename according to the configuration, and write the file content into the file system.
Difference between Loader and Plugin? Thoughts on writing Loader, Plugin
Difference
Loader is a file loader that can load resource files and perform some processing on them, such as compiling and compressing, and finally package them together into the specified file.
Plugin gives webpack various flexible functions, such as package optimization, resource management, environment variable injection, etc. The purpose is to solve other things that loader cannot achieve.
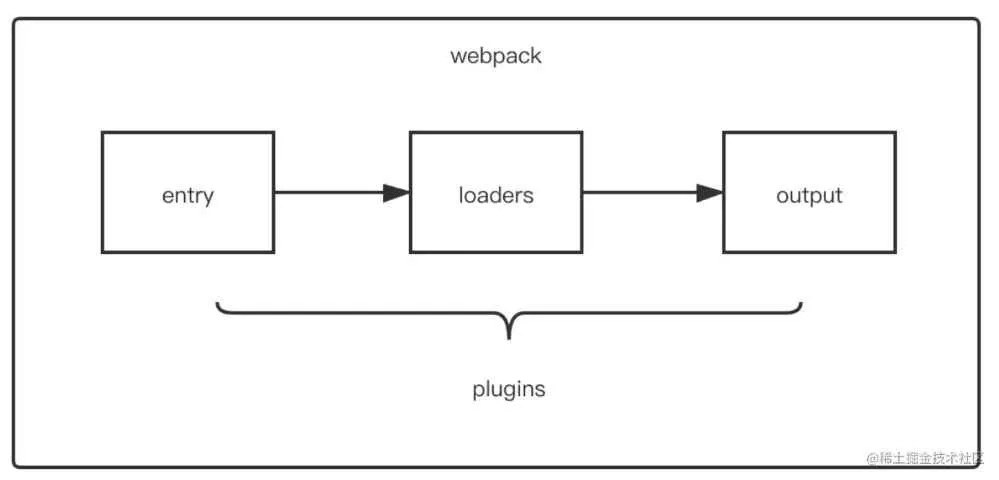
From the overall operation timing, we can see the difference between the two:
Loader runs before the files are packaged.
Plugins work throughout the entire compile cycle.
There are many events broadcasting during the lifecycle of Webpack. Plugin can listen to these events and change the output results at the right time through the API provided by Webpack.
For loader, its essence is a transformer, compiling file A into file B, operating on files, such as transforming A.scss or A.less into B.css, a simple file conversion process.
Writing loaders
Before writing a loader, you need to understand its nature.
Its essence is a function. The this in the function is filled by webpack as context, so we cannot set the loader as an arrow function.
The function accepts a parameter, which is the source content of the file passed to the loader by webpack.
The this in the function is an object provided by webpack, and it can obtain all kinds of information required by the current loader.
The function contains asynchronous or synchronous operations. Asynchronous operations are returned through this.callback, and the return value is required to be string or Buffer.
Example code:
| |
Generally in the process of writing loaders, keep the functions simple and avoid doing multiple functions.
Like the conversion from less file to css file, it is not completed in one step, but by the chain call of less-loader, css-loader, and style-loader.
Write plugins
Since webpack is based on the publisher-subscriber mode, it will broadcast many events during the run lifecycle. By listening to these events, the plugins can execute their tasks at specific stages.
We have learned before that just two core objects are created during the webpack compile:
Compiler: It contains all configuration information of the webpack environment, including options, loader, and plugin, and hooks related to the whole life cycle of webpack.
Compilation: Acts as the parameters of the built-in event callback function of the plugin, and includes the current module resources, compiled resources, changed files, and the status information of the tracked dependencies. When a file change is detected, a new Compilation will be created.
If you want to implement plugins yourself, you also need to follow certain specifications:
The plugin must be a function or an object with an apply method so that it can access the compiler instance.
The compiler and compilation objects passed to each plugin are the same reference, so it is not recommended to modify them.
Asynchronous events need to notify Webpack to enter the next process by calling the callback function when the plugin has completed the task, otherwise it will get stuck.
The template for implementing plugins is as follows:
| |
When the emit event occurs, it means that the conversion and assembly of the source files have been completed. We can read the resources, code blocks, modules and their dependencies that will be finally output, and we can modify the content of the output resources.
Improving the build speed of webpack
Optimize the loader configuration
Responsible use of resolve.extensions
Optimize resolve.modules
Optimize resolve.alias
Use DLLPlugin
Use cache-loader
Enable Multi-threading in Terser
Responsible use of sourceMap
How is webpack hot update done?
Create two servers with webpack-dev-server: Services providing static resources (express) and Socket services.
The express server directly provides static resource services (resources packed are directly requested and parsed by the browser).
The socket server is a long connection of websocket, which allows two-way communication.
When the socket server listens to changes in the corresponding module, it will generate two files, .json (manifest file) and .js file (update chunk).
Through the long connection, the socket server can directly send these two files to the client (browser).
After getting the two new files, the browser loads these files through the HMR runtime mechanism and updates the modified modules.
Common Loaders in webpack
style-loader: Adds css to the inline style tag in the DOM.
css-loader: Allows css files to be imported through require and returns css code.
less-loader: Handles less files.
sass-loader: Used to process sass files.
postcss-loader: Uses postcss to process CSS.
autoprefixer-loader: Handles CSS3 property prefixes, is now deprecated; it is recommended to use postcss directly.
file-loader: Distributes files to the output directory and returns the relative path.
url-loader: Similar to file-loader, but can return a Data Url when the file size is smaller than the set limit.
html-minify-loader: Compresses HTML.
babel-loader: Uses babel to convert ES6 files to ES5.
ommon Loaders in Plugin
AggressiveSplittingPlugin: Splits the original chunk into smaller chunks.
BabelMinifyWebpackPlugin: Uses babel-minify for compression.
BannerPlugin: Adds a banner to the top of each generated chunk.
CommonsChunkPlugin: Extracts common modules shared between chunks.
CompressionWebpackPlugin: Prepares compressed versions of assets, serving them with Content-Encoding.
ContextReplacementPlugin: Overwrites the inferred context of the require expression.
CopyWebpackPlugin: Copies individual files or entire directories to the build directory.
DefinePlugin: Allows the configuration of global constants at compile time.
DllPlugin: Splits packages to greatly reduce build time.
EnvironmentPlugin: Abbreviation for the process.env key in DefinePlugin.
ExtractTextWebpackPlugin: Extracts text (CSS) from a bundle into a separate file.
HotModuleReplacementPlugin: Enables Hot Module Replacement (HMR).
HtmlWebpackPlugin: Simplifies creation of HTML files for server access.
I18nWebpackPlugin: Adds internationalization support to the bundle.
IgnorePlugin: Excludes certain modules from the bundle.
LimitChunkCountPlugin: Sets the minimum/maximum limit for chunks, to refine and control chunk sizing.
LoaderOptionsPlugin: Used for migration from webpack 1 to webpack 2.
MinChunkSizePlugin: Ensures chunk sizes exceed specified limits.
NoEmitOnErrorsPlugin: Skips when encountering build errors during the output phase.
NormalModuleReplacementPlugin: Substitutes resources that match a regular expression.
NpmInstallWebpackPlugin: Automatically installs missing dependencies during development.
ProvidePlugin: Allows use of modules without having to import/require.
SourceMapDevToolPlugin: Provides more granular control of the source map.
EvalSourceMapDevToolPlugin: Provides more granular control of the eval source map.
UglifyjsWebpackPlugin: Controls the version of UglifyJS in the project.
ZopfliWebpackPlugin: Precompresses resources using node-zopfli.
What are the commonly used Git commands and their functions?
Basic Operations
git init: Initializes the repository, default branch is master.git add .: Stages all changes in the files to the staging area.git add <specific file path+name>: Stages changes of specific files to the staging area.git diff: Shows what will be added after using git add.git diff— staged: Shows what will be committed when using git commit.git status: Shows the status of the current branch.git pull <remote repository name> <remote branch name>: Pulls and merges the given remote branch with the current local branch.git pull <remote repo name> <remote branch name>:<local branch name>: Pulls and merges the remote branch with the specified local branch.git commit -m “<comment>”: Commits the changes to the local repository with a comment.git commit -v: Shows all diff information during commit.git commit — amend [file1] [file2]: Resets previous commit and includes changes of specified files.
Commit Rules
feat: New feature, adds a function.fix: Bugs fixing.refactor: Code refactoring.docs: Document modification.style: Code formatting modification, not css modification.test: Test cases modification.chore: Other modifications, like build workflow, dependency management.
Branch Operations
git branch: Lists all local branches.git branch-r: Lists all remote branches.git branch -a: Lists all local and remote branches.git merge <branch name>: Merges branches.git merge— abort: Cancels the branches merging in case of conflicts, and resets everything to before the merge.git branch <new branch name>: Creates a new branch based on the current branch.git checkout — orphan <new branch name>: Creates a new empty branch (that will still contain all files from the previous branch).git branch -D <branch name>: Deletes a local branch.git push <remote repository name>:<branch name>: Deletes a remote branch.git branch <new branch name> <commit ID>: Restores a deleted branch from commit history.git branch -m <old branch name> <new branch name>: Renames a branch.git checkout <branch name>: Switches to a specified local branch.git checkout <remote repository name>/<branch name>: Switches to a specified remote branch.git checkout -b <new branch name>: Creates a new branch based on the current branch and switches to this new branch.
Remote Operations
git fetch [remote]: Downloads all changes from remote repository.git remote -v: Lists all remote repositories.git pull [remote] [branch]: Pulls and merges the specified remote branch with the current local branch.git fetch: Fetches the latest version information from the server, without merging.git push [remote] [branch]: Pushes the local specified branch to the remote repository.git push [remote]— force: Forces the push of the current branch to the remote repository, even in case of conflicts.git push [remote]— all: Pushes all branches to the remote repository.
Reverting Operations
git checkout [file]: Resets the given file from the staging area to the work tree.git checkout [commit] [file]: Restores the given file of a certain commit to the staging area and work tree.git checkout.: Resets all files from the staging area to the work tree.git reset [commit]: Resets the local HEAD pointer to a specified commit and resets the staging area but not the working directory.git reset— hard: Resets the staging area and the work directory to match with the most recent commit.git reset [file]: Resets the specified file in the staging area which matches with the last commit, leaving the work directory unchanged.git revert [commit]: The latter’s all changes will be cancelled by the former, and it is applied to the current branch.reset: Real rollback, the commit records after the target version are all lost.revert: Also rollback, this rollback operation is equivalent to a submission, the commit records after the target version are also all there.
Stash Operations
git stash: Temporarily moves uncommitted changes.git stash pop: Restores the last stashed work state and removes it from the stash.git stash list: Lists all stashed work states.git stash apply <stash’s name>: Restores the stashed work states but does not remove them from the stash.git stash clear: Clears all stashed work states.git stash drop <stash’s name>: Deletes a specific stashed work state.
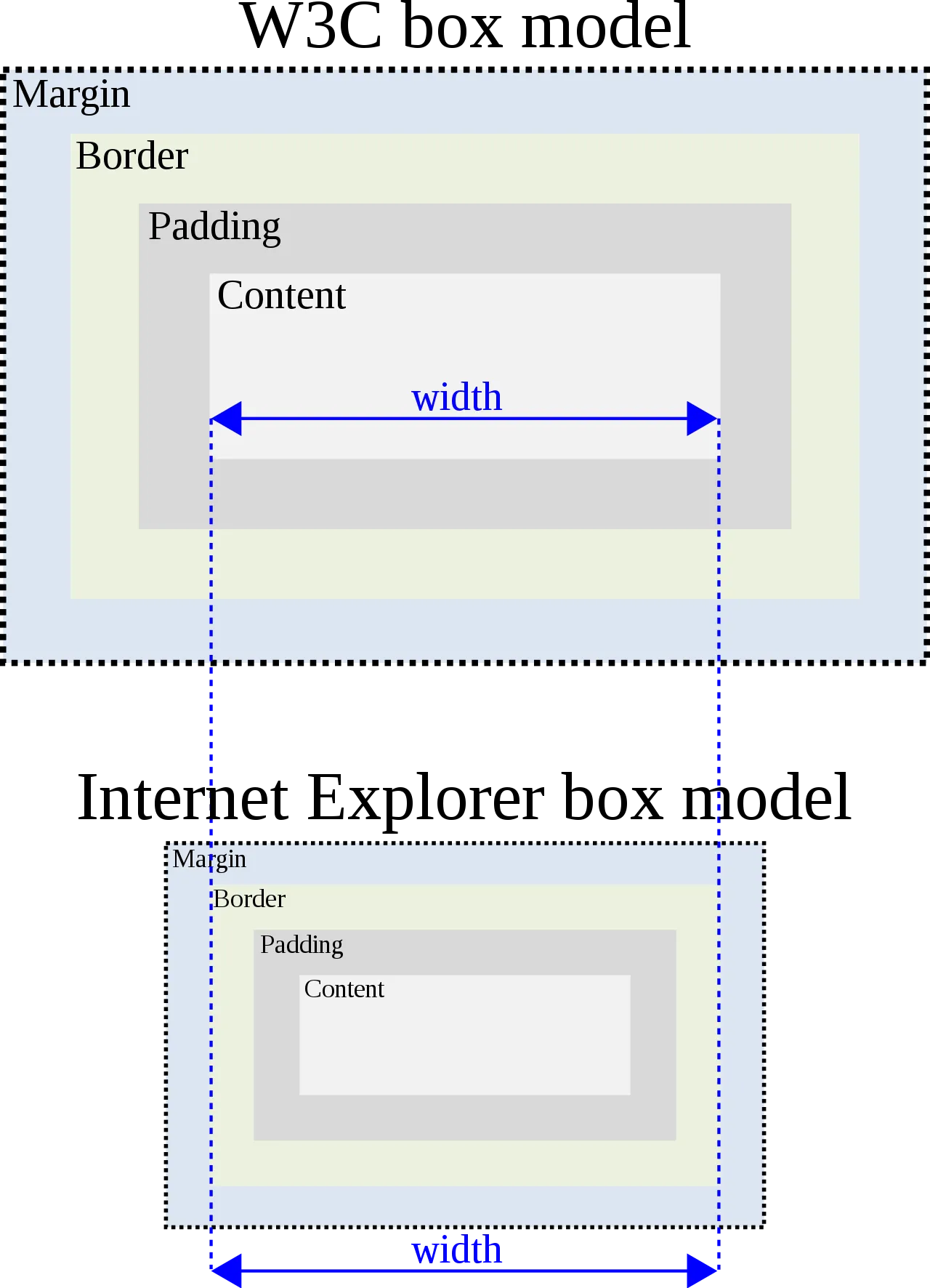
What is the standard CSS box model and how does it differ from the box model found in older versions of IE?
Standard (W3C) box model: width = content width + border + padding + margin
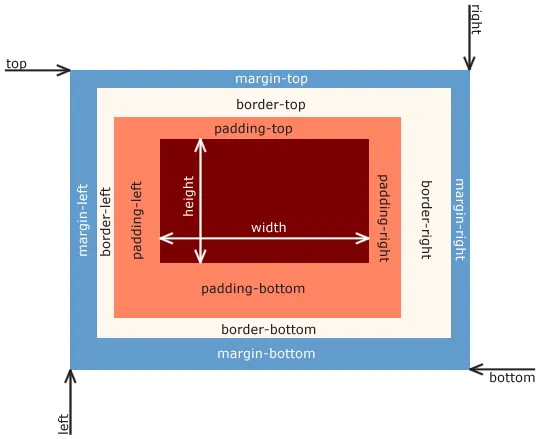
Older versions of IE box model: width = content width (which includes the border and padding) + margin
What is the CSS Specificity?
CSS specificity refers to the priority level of a style being applied during conflicts. The calculation of specificity is determined based on the type and quantity of selectors. The weight values of selectors from high to low are: !important > inline styles > ID selector > class selector, attribute selector and pseudo-class selector > tag selector and pseudo-element selector. Specifically, the weight of the ID selector is 100, the weight of the class selector, attribute selector and pseudo-class selector is 10, and the weight value of the tag selector and pseudo-element selector is 1. When there is a styling conflict, the style with the higher weight value will override the one with the lower weight value.
What are the CSS selectors and what attributes can be inherited?
Common selectors include:
id selector (#content), class selector (.content), tag selector (div, p, span, etc.), adjacent selector (h1+p), child selector (ul>li), descendants selector (li a), universal selector (*), attribute selector (a[rel = "external"]), and pseudo-class selector (a:hover, li:nth-child).
Inheritable style properties: font-size, font-family, color, ul, li, dl, dd, dt;
Non-inheritable style properties: border, padding, margin, width, height.
What are the points of origin for the ‘relative’ and ‘absolute’ values of the position property?
First of all, when using position, one should bear in mind the rule of “child absolute, parent relative”.
relative (Relative positioning): establishes a relative positioning system, the positioning origin is the location of the element itself.
absolute (Absolute positioning): establishes an absolute positioning system, the positioning origin is the top-left corner of the nearest parent element that has a position value of absolute or relative.
fixed (Not supported by older versions of IE): establishes an absolute positioning system, positioning is relative to the browser window.
static: Default value. No positioning, elements appear in the regular flow (ignores top, bottom, left, right, z-index declarations).
inherit: Specifies that the position property should be inherited from the parent element.
New Attribute Update
sticky: (additional attribute, may not have ideal compatibility at the moment), can set position to be sticky by adding a value to one of the top, bottom, right, left properties.
Note:
When using sticky, one must specify at least one of top, bottom, left, right, otherwise the element will remain in relative positioning;
sticky only works within its parent element, and the parent element’s height must be taller than the ‘sticky’ height;
The parent element cannot contain the overflow:hidden or overflow:auto properties.
What new features does CSS3 offer?
Regarding the new features added in CSS, they include:
Selectors;
Rounded corners border-radius;
Multi-column layouts;
Shadows shadow and reflections reflect;
Text effects text-shadow;
Text rendering text-decoration;
Linear gradients gradient;
Rotate rotate/Scale scale/Skew skew/Move translate;
Media queries @media;
RGBA and transparency;
@font-face property;
Multiple background images;
Box sizing;
Speech (aural style sheets).
What’s the principle of creating a triangle with pure CSS?
Implementation Steps: 1. Ensure that the element is a block-level element; 2. Set the borders of the element; 3. Use transparent color for the borders that do not need to be displayed.
css:
| |
html:
| |
What are the methods to hide an element?
Using the display property: By setting the display property of an element to none, the element will not take up any space on the page and will not affect other elements.
Using the visibility property: By setting an element’s visibility property to hidden, the element will be invisible on the page but still take up space.
Using the opacity property: By setting an element’s opacity property to 0, the element will be invisible on the page but still take up space.
Using the position property: Set the element’s position property to absolute or fixed, then move the element off the screen or make it exceed the scope of the container. The element will be invisible on the page but still take up space.
Using the z-index property: If you set the z-index property of an element to a negative value, the element will be invisible on the page but still take up space.
Using the clip property: Set the clip property of an element to a rectangular area, then the element will only display the part within the rectangular area, the rest will be clipped off.
Set height: 0: sets the height of an element to 0 and removes the border;
Set filter: blur(0): is a CSS3 property. The larger the value in the parenthesis, the greater the degree of Gaussian blur of the image. When it reaches a certain level, the image can disappear.
Set transform: scale(0): scales an element infinitely small, the element will be invisible, but the original position of the element will be preserved.
Combine multiple CSS files, and try to reduce HTTP requests Do not add a unit when the attribute value is 0 Place the CSS files at the top of the page Avoid descendant selectors, overly restrictive and chained selectors Use compact syntax Avoid unnecessary repetition Use semantic naming for easy maintenance Try to use Simplify the rules, merge repeated rules for different classes as much as possible Adhere to the box model rules Priority: Each selector in CSS has a priority. You can determine which style definition will be applied by their priority. If the styles in two class definitions conflict with each other, you can resolve the conflict by adjusting the priority. Parent Selector: You can use a parent selector to limit the scope of the style and thereby avoid conflicts. For example, if the styles in two class definitions are applied to different child elements of a certain parent element, you can use a parent selector to limit the scope of the style and thereby avoid conflicts. Namespaces: You can use namespaces to distinguish the style definitions of different modules or components to avoid conflicts. For example, you can add different namespace prefixes to the class definitions of different modules or components to distinguish them from each other. Scoped Styles: You can use scoped styles to limit styles to specific components or modules to avoid conflicts with styles from other components or modules. Scoped styles are a special style provided by the Vue framework, which can be achieved by adding the scoped attribute in the style tag. Firstly, margin collapse is margin-collapse. The margins of two adjacent boxes (may be siblings or ancestors) can combine into a single margin. This manner of merging margins is called collapsing, and the combined margin is called a collapsed margin. The result of the collapse follows these calculation principles: When the two adjacent outer margins are positive, the result of the collapse is the larger of the two; When the two adjacent outer margins are negative, the result of the collapse is the larger absolute value of the two; When one margin is positive and the other is negative, the result of the collapse is the sum of the two. The 1px problem refers to: on some Retina screen devices, the 1px of the mobile web page will become very thick, presenting more than 1px effect. The reason is simple — the 1px in CSS cannot be equated with the 1px on the mobile device. Their proportional relationship has a special property to describe: Open the Chrome browser, start the mobile debugging mode, and output the value of this devicePixelRatio in the console. Select the iPhone6/7/8 series, and the output result is 2: which means that the set 1px CSS pixel will actually use 2 physical pixel units to render on this device, so the actual observation will definitely be thicker than 1px. Here are three ways to solve the 1px problem: Approach 1: Write 0.5px directly If the 1px style is written like this before: You can first get the value of window.devicePixelRatio in JS, and then give this value to the data in CSS through JSX or template syntax to achieve this effect (here it is demoed with JSX syntax): Then you can hit the case where devicePixelRatio is a certain value with the attribute selector in CSS, such as trying to hit devicePixelRatio when it is 2: Just change 1px to 1/devicePixelRatio, this is the simplest method so far. The disadvantage of this method is that its compatibility is not good, IOS system needs version 8 or above, and the Android system is just not compatible. Approach 2: Pseudo elements magnify first and then shrink This method has higher feasibility and better compatibility. The only downside is that the code will increase. The idea is to enlarge first and then shrink: a ::after pseudo-element is appended behind the target element, and after this element is layout as absolute and fully stretched on the target element, its width and height are both set to twice the target element, and the border value is set to 1px. We then take advantage of the ability to scale in CSS animation effects to shrink the entire pseudo-element to 50% of its original size. At this time, the width and height of the pseudo-element just match the original target element, and the border is also reduced to half of 1px, indirectly achieving the effect of 0.5px. The code is as follows: Approach 3: Solve it by viewport scaling This idea is to target a few key attributes in the meta tag: For the pages with a pixel ratio of 2, the whole page is scaled to 1/2 of its original size. So the 1px style that originally occupied 2 physical pixels now occupies the standard one physical pixel. Depending on the pixel ratio, this scale can be calculated as a different value, implemented in js code as follows: This solves the problem, but the side effects of doing so are also significant, as the entire page has been scaled down. The 1px has been processed to the size of the physical pixel, which is perfect for displaying the border on a mobile phone. However, some content that originally did not need to be shrunk, such as text, pictures, etc., has also been indiscriminately downsized. BFC dictates how the internal Block Box is laid out. A page is made up of many Boxes, and the type and display properties of the elements determine the type of this Box. Different types of boxes will participate in different Formatting Contexts (containers that decide how to render the document), therefore, elements within the Box will render in different ways, that is to say, elements inside the BFC and elements outside the BFC will not affect each other. Positioning scheme: The internal boxes will be placed one after the other in the vertical direction; The vertical distance of the box is determined by the margin, the margin of two adjacent Boxes belonging to the same BFC will overlap; The left side of each element’s margin box is in contact with the left side of the containing block’s border box; The BFC area does not overlap with float boxes; BFC is an isolated independent container on the page, and elements inside the container will not affect elements outside; When calculating the height of the BFC, floating elements will also participate. Meeting any of the following conditions can trigger BFC: Root element changes, i.e., html; The float value is not The ove The display value is The position value is The three-column layout generally refers to the layout where the left and right columns have a fixed width and the middle adapts automatically. The specific implementation of the three-column layout is as follows: Using absolute positioning, the two columns on the left and right are set as absolute positioning, and the middle one is set with corresponding direction and size of margin values. Using flex layout, the left and right columns are set with a fixed size and the middle one is set with flex:1. Using floating, the left and right columns are set with a fixed size and corresponding direction for floating. The middle column is set with margin values for the left and right directions, note that in this method, the middle column must be placed last. Holy Grail Layout, using floating and negative margins. The parent element sets padding on the left and right, all three columns are set to float left, and the middle column is placed at the front, the width is set to the width of the parent element, so the two columns behind are pushed to the next line, set a negative margin value to move them to the previous line, then use relative positioning to position them on either side. Double-wing layout, compared to the Holy Grail layout, the retention of the left and right positions is achieved through the margin value of the middle column, not through the padding of the parent element. Essentially, it’s also achieved through floating and negative outer margins. It is When the parameter is set to scroll, a scrollbar will always appear; When the parameter is set to auto, a scrollbar will appear when the content of the child element is larger than the parent element; When the parameter is set to visible, the overflow content will appear outside of the parent element; When the parameter is set to hidden, the overflow is hidden; Embedded Style: Pros: Convenient to write, high weight; Cons: Does not separate structure and style; Inline Style: Pros: Separates structure and style; Cons: Not completely separate; External Style: Pros: Completely separates structure and style; Cons: Needs to be imported before it can be used; The display property specifies the type of box that the element should generate; The position property specifies the positioning type of the element; The float property is a layout method that defines the direction in which the element floats; Stacking Results: It’s a bit like a priority mechanism. The values of position — absolute/fixed have the highest priority. When they are present, float does not work, and the value of display needs to be adjusted. float or absolute positioned elements must be block elements or tables. Reflow, reflow: A part (or all) of the render tree needs to be rebuilt due to changes in elements’ dimensions, layout, hiding, etc. Repaint, repaint: When some elements in the render tree need to update attributes, and these attributes only affect the appearance, style, but do not affect the layout, it is called repaint, such as color changes, etc. Adding or deleting visible dom elements; The position of the element has changed; The size of the element has changed, such as the change of margin, width, height and other geometric properties; Content changes, such as image size, font size changes, etc.; Page rendering initialization; The size of the browser window changes, such as when a resize event occurs, etc.; Reflow (rearrangement) will definitely trigger repaint. Transform is a composite property, animating a composite property through transition/animation will create a composite layer, allowing the animated elements to be animated in a separate layer. Typically, the browser will first render the content of a layer into a bitmap, then upload it as a texture to the GPU, and as long as the content of the layer does not change, there is no need for repaint. The browser will create a new frame through recomposition. Top/left are layout properties, changes to these properties will cause reflow/relayout. This so-called reflow refers to the process of CSS calculation -> layout -> repaint for these nodes and other nodes influenced by them. The browser needs to repaint the entire layer and re-upload it to the GPU, which causes a great deal of performance overhead.What are the methods for CSS optimization and performance improvement?
!important as little as possible, choose other selectors insteadHow to avoid conflicts if there are two identical class definitions in CSS?
What is margin collapse? What is the result of the collapse?
How to solve the 1px problem?
1
window.devicePixelRatio = physical pixel of the device / CSS pixel.
1
border:1px solid #333
1
<div id="container" data-device={{window.devicePixelRatio}}></div>
1
2
3
#container[data-device="2"] {
border: 0.5px solid #333
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#container[data-device="2"] {
position: relative;
}
#container[data-device="2"]::after{
position:absolute;
top: 0;
left: 0;
width: 200%;
height: 200%;
content: "";
transform: scale(0.5);
transform-origin: left top;
box-sizing: border-box;
border: 1px solid #333;
}
1
<meta name="viewport" content="initial-scale=0.5, maximum-scale=0.5, minimum-scale=0.5, user-scalable=no">
1
2
3
const scale = 1 / window.devicePixelRatio;
// Here metaEl refers to the Dom corresponding to the meta tag
metaEl.setAttribute('content', `width=device-width,user-scalable=no,initial-scale=${scale},maximum-scale=${scale},minimum-scale=${scale}`);
Understanding of the BFC Specification (Block Formatting Context)
none (default);rflow value is not visible` (default);inline-block, table-cell, table-caption;absolute or fixed.Implementation of the three-column layout
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
.outer {
position: relative;
height: 100px;
}
.left {
position: absolute;
width: 100px;
height: 100px;
background: tomato;
}
.right {
position: absolute;
top: 0;
right: 0;
width: 200px;
height: 100px;
background: gold;
}
.center {
margin-left: 100px;
margin-right: 200px;
height: 100px;
background: lightgreen;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
.outer {
display: flex;
height: 100px;
}
.left {
width: 100px;
background: tomato;
}
.right {
width: 100px;
background: gold;
}
.center {
flex: 1;
background: lightgreen;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
.outer {
height: 100px;
}
.left {
float: left;
width: 100px;
height: 100px;
background: tomato;
}
.right {
float: right;
width: 200px;
height: 100px;
background: gold;
}
.center {
height: 100px;
margin-left: 100px;
margin-right: 200px;
background: lightgreen;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
.outer {
height: 100px;
padding-left: 100px;
padding-right: 200px;
}
.left {
position: relative;
left: -100px;
float: left;
margin-left: -100%;
width: 100px;
height: 100px;
background: tomato;
}
.right {
position: relative;
left: 200px;
float: right;
margin-left: -200px;
width: 200px;
height: 100px;
background: gold;
}
.center {
float: left;
width: 100%;
height: 100px;
background: lightgreen;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
.outer {
height: 100px;
}
.left {
float: left;
margin-left: -100%;
width: 100px;
height: 100px;
background: tomato;
}
.right {
float: left;
margin-left: -200px;
width: 200px;
height: 100px;
background: gold;
}
.wrapper {
float: left;
width: 100%;
height: 100px;
background: lightgreen;
}
.center {
margin-left: 100px;
margin-right: 200px;
height: 100px;
}
How to make Chrome support text less than 12px?
1
2
3
4
5
.shrink {
-webkit-transform: scale(0.8);
-o-transform: scale(0.8);
display: inline-block;
}
What is the execution order of :link, :visited, :hover, :active?
L-V-H-A, representing l(link)ov(visited)e h(hover)a(active)te. This can be remembered by using the two words “like” and “hate” to summarize.How does the CSS property ‘overflow’ handle a situation when the content of the content area of the element overflows?
Comparison of the pros and cons of CSS style import methods.
What happens after position is stacked with display, overflow, float?
What is reflow (rearrangement) and repaint and their differences?
Why use transform to center?